Хто працював чи працює у Windows, у того в голові при фразі "розпізнавання тексту" відразу виникає асоціація з "ABBYY FineReader", ціна програми на момент написання статті отака:

Чи є подібні програми в Linux? Такого рівня немає, хоча сама компанія ABBYY щось там робить для Linux, але теж за гроші. З безкоштовних програм варіантів лише два: CuneiForm та Tesseract. CuneiForm багато хто розхвалює аж до дифірамбів, але я сьогодні буду говорити саме про Tesseract, оскільки користуюся ним сам, і можливостей софту для мене вистачає.
Встановлювати будемо саму програму, візуальну оболонку для неї — програму gImageReader — та мовні файли включно із функцією перевірки орфографічних помилок.
Встановлювати будемо на Arch Linux з допомогою AUR-хелпера YAY, а також на Ubuntu-подібні дистрибутиви, щоб убунтоводи не образилися 😉
Arch Linux
sudo pacman -S tesseract tesseract-data-ukr gimagereader-gtk hunspell
yay hunspell-uk # це, власне, й потрібно для виявлення орфографічних помилокUbuntu/Linux Mint
sudo apt update
sudo apt install tesseract-ocr tesseract-ocr-ukr gimagereaderВ результаті ми отримуємо повністю достойну програму розпізнавання тексту, яка запускається із меню графічних програм під назвою gImageReader:
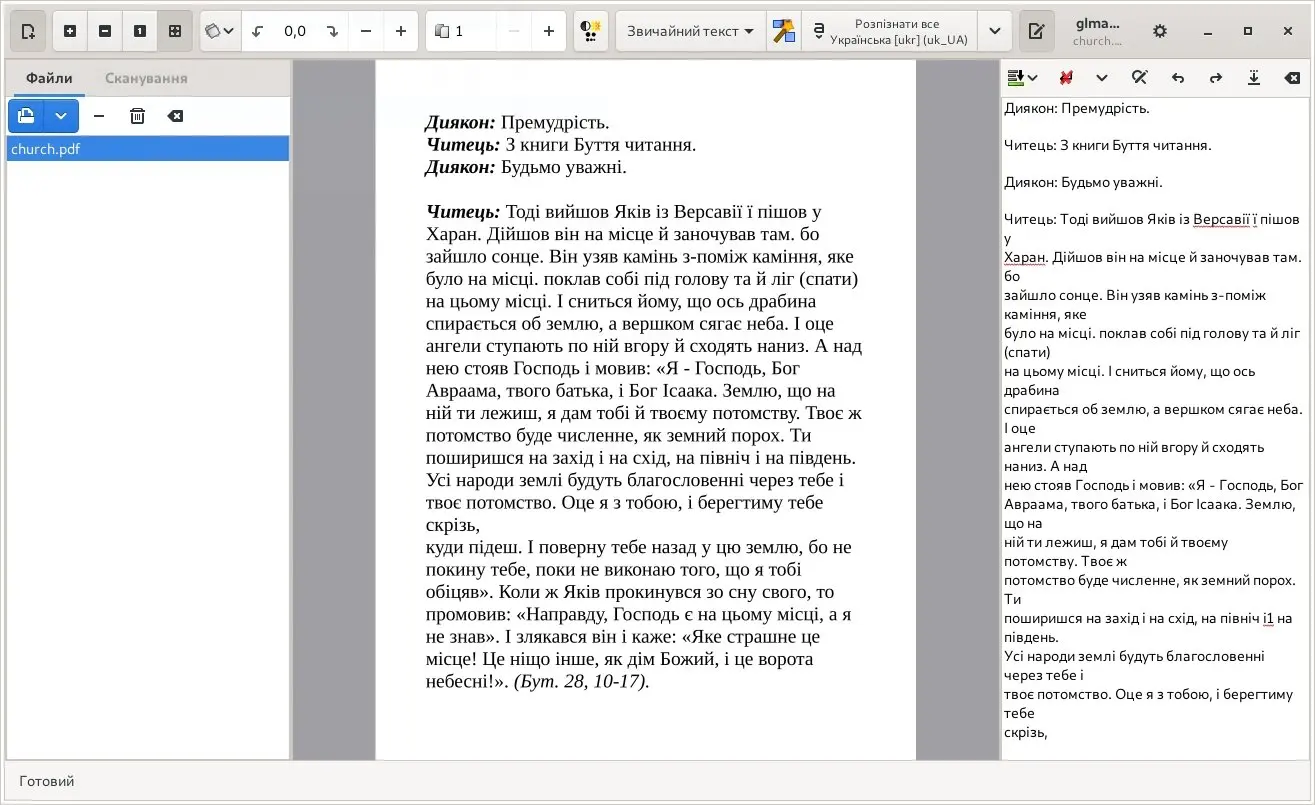
Так, функцій тут небагато, але тих, що є, для роботи вистачає з головою. Зате величезний плюс у тому, що весь цей набір повністю безкоштовний, а це величезна економія 😉
Працюй собі в задоволення!





леле, я востаннє цікавився (трішечки) темою років зо п’ять тому… обидва пакети вже існували, але толку від них не дуже було. треба знову спробувать (хоча, направду, зараз немає потреби щось розпізнавати, але хто зна, може знадобитися колись). подякував за допис!